Visão Geral
O Apache Kakfa é uma plataforma open-source de processamento de streams desenvolvida pela Apache Software Foundation, escrita em Scala e Java. Essa ferramenta foi desenvolvida inicialmente na LinkedIn e liberada em 2011 para a comunidade.
A parte central do Kafka é composta do Broker, intermediário encarregado de receber, armazenar e transmitir as mensagens. As APIs de Consumer e Producer permitem respectivamente de receber e enviar mensagens. O Apache Kafka armazena as mensagens utilizando um mecanismo de chave/valor.
Além dessas funcionalidades de troca de mensagen existem ferramentas desenvolvidos ao redor da ferramenta:
- Kafka Connect
-
que permite conectar Kafka com sistemas externos como banco de dados (SQL e NoSQL), índice de pesquisa como Elasticsearch, Sistemas de Arquivos e outros sistemas de mensageria como JMS ou RabbitMQ por exemplo. Essa integração pode ser feita na entrada de dados e na saída. Nesse site da Confluent encontrarão uma lista de conectores prontos, mas a API Connector pode ser utilizada para criar novos. Permite efetuar ETL em tempo real.
- Schema Registry
-
permite definir a estrutura das mensagens criando schemas, versionar os mesmos e distribuí-los para os Consumers e Producers.
- Stream API
-
ajuda na criação de fluxos de dados, pemitindo processar esses dados e criar novos fluxos e filas.
- KSQL
-
Ferramenta escrita em cima da API de Stream para criar fluxos usando SQL.
Teoria sobre funcionamento do Kafka
Topics, partitions e offsets
Topic = fluxo de dados, definido por um nome
Os topics são divididos em partições Cada partição é ordenada, e cada mensagem em uma partição tem um identificador incremental, chamado de offset
O número de partições deve ser definido na criação do Topic e determina quantos consumers podem ler dados simultaneamente de um mesmo Topic.
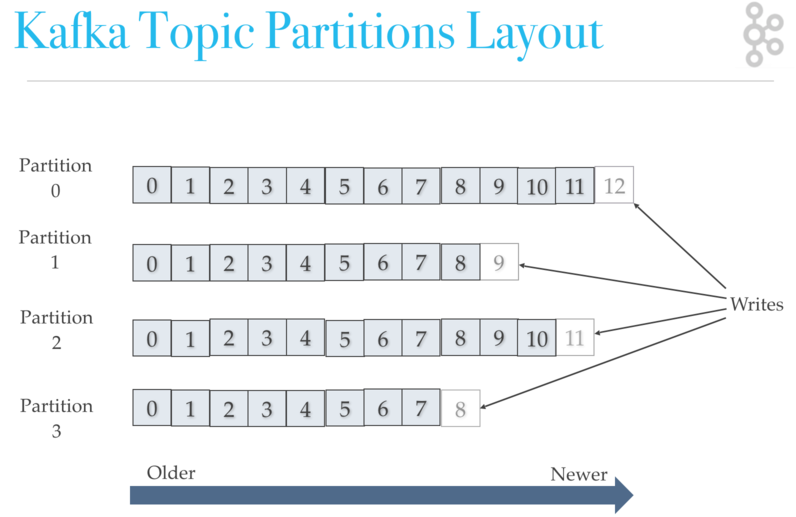
Coordenadas de uma mensagem: Partição 1 Offset 2 Partição 2 Offset 4 … A ordenação é garantida dentro de uma partição e não entre as partições. Quando um dado é escrito em uma partição ele não pode ser mudado. Os dados são enviadas aleatoriamente para uma partição a menos que tenha uma chave.
Brokers
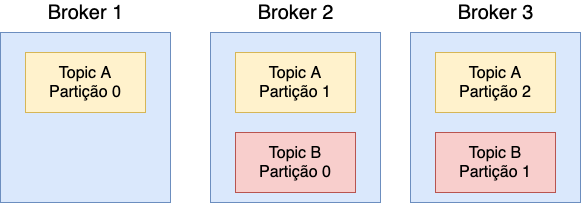
São os nós de uma partição, um cluster Kafka é composto de vários Brokers É recomendado começar com 3 brokers.
Exemplo com 2 tópicos, A com 3 partições e B com 2. As partições são armazenadas em Brokers diferentes.
Replicação, duplicação das partições:
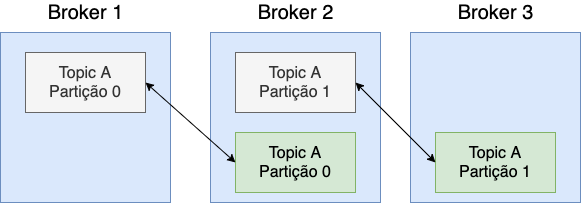
Em um determinado momento um dos Brokers é o líder de uma determinada partição (em verde acima). Os outros Brokers sincronizam os dados. Uma partição tem um líder e várias réplicas - ISR (In-Sync Replica).
Producers
Os Producers escrevem dados nos Topics e sabem automaticamente em qual broker e qual partição deve escrever. Em caso de falhas de Broker eles se recuperam automaticamente.
Se não existir chave por uma mensagem ela é enviada utilizando Round Robin em uma das partições. O Producer pode receber um reconhecimento (acknowledgement) para saber se uma mensagem foi entregue para um broker. Existem três níveis de reconhecimento:
-
Ack = 0: o Producer não espera o reconhecimento, existe a possibilidade de perder dados, mas é mais performático.
-
Ack = 1: o Producer espera o Líder enviar um reconhecimento, o risco de perder dados é limitado.
-
Ack = all: o Producer espera o Líder e todos os réplicas enviar um reconhecimento, assim evitando perda de dados. Essa abordagem é mais custosa, e a performance depende do número de replicações do Topic.
Se o Producer envia uma chave, existe a garantia de que todas as mensagens com a mesma chave serão enviadas para o mesmo topic. Isso é útil quando precisa que as mensagens sejam lidas em uma ordem em particular. Um hash da chave é criado para garantir o envio para uma mesma partição. Uma chave pode ser de qualquer tipo.
Consumer e Consumer Groups
Consumer leiam mensagens dos topics, eles sabem de qual broker ler os dados. Com a opção bootstrap-server, precisamos conhecer somente um dos brokers, o mesmo retornará para o consumer todos os brokers e as partições que cada um contém para um determinado topic. Em caso de falhas nos brokers, os consumers sabem se recuperar. Ponto importante, os dados são lidos na ordem dentro uma partição. Os dados são lidos em paralelo entre cada partição. As mensagens são lidas pelos Consumers em grupos de consumidores (Consumer Groups). Cada consumer dentro de um grupo consome de partições exclusivas, não existem dois consumers no mesmo grupo lendo da mesma partição. Caso tenha mais consumers que partições esses a mais ficaram ociosos. Os Consumers utilizam automaticamente um GroupCoordinator e um ConsumerCoordinator para vincular um consumer a uma ou mais partições.
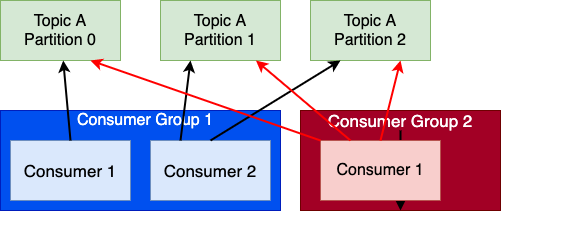
Vimos que o número de partições determina quantos consumers podem ler dados simultaneamente de um mesmo Topic. É aconselhável escolher um número mais alto de partições do que se prevê de Consumers incialmente de maneira a facilitar a escalabilidade das aplicações.
Primeiros passos com Kafka
Baixar as imagens utilizadas no treinamento:
docker image pull lensesio/fast-data-dev:2.3
docker image pull confluentinc/cp-zookeeper:5.4.1
docker image pull confluentinc/cp-server:5.4.1
docker image pull confluentinc/cp-schema-registry:5.4.1
docker image pull cnfldemos/cp-server-connect-datagen:0.2.0-5.4.0
docker image pull confluentinc/cp-ksql-server:5.4.1
docker image pull confluentinc/cp-ksql-cli:5.4.1
docker image pull confluentinc/ksql-examples:5.4.1
docker image pull confluentinc/cp-kafka-rest:5.4.1Nesse exercício vamos utilizar o docker-compose disponível no endereço: https://raw.githubusercontent.com/confluentinc/examples/v5.4.1/cp-all-in-one/docker-compose.yml
Para começar executar o serviço broker, o mesmo dependendo do Zookeeper esse último será inicializado também:
docker-compose up -d brokerVerificar que os serviços broker e zookeeper estão rodando (State Up):
docker-compose ps
Name Command State Ports
------------------------------------------------------------------------------------------
broker /etc/confluent/docker/run Up 0.0.0.0:9092->9092/tcp
zookeeper /etc/confluent/docker/run Up 0.0.0.0:2181->2181/tcp, 2888/tcp, 3888/tcpCom a configuração feita no docker-compose, o Kafka estará disponível para conexão com localhost na porta 9092 (por exemplo para usar ferramentas da linha de comando do PC), e com nome broker na porta para conexão entre containers. Dentro da rede Docker o broker estará disponível no endereço broker:29092.
Agora vamos iniciar dois containers, um producer (com nome producer), um primeiro consumer com nome consumer1, e um container kafka-client que utilizaremos para interagir com o cluster:
docker run --name producer --rm -it --net=cp-all-in-one_default lensesio/fast-data-dev:2.3 bash
docker run --name kafka-client --rm -it --net=cp-all-in-one_default lensesio/fast-data-dev:2.3 bash
docker run --name consumer1 --rm -it --net=cp-all-in-one_default lensesio/fast-data-dev:2.3 bashNo producer, criar uma fila e em seguida executar kafka-console-producer:
$ kafka-topics --bootstrap-server broker:29092 --create --topic first --partitions 3 --replication-factor 1
$ kafka-topics --bootstrap-server broker:29092 --list
__confluent.support.metrics
_confluent-license
_confluent-metrics
first
$ kafka-console-producer --broker-list broker:29092 --topic first --property "parse.key=true" --property "key.separator=:"Para enviar os dados no producer basta digitar a mensagem e apertar Enter.
Conectar o consumer1 na fila:
kafka-console-consumer --bootstrap-server broker:29092 --topic first --group app1Descrever o consumer-group na máquina local:
$ kafka-consumer-groups --bootstrap-server localhost:9092 --group app1 --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
app1 first 0 0 0 0 consumer-1-77ceb54e-e82f-42e3-bbe6-5f1d6700edaf /172.31.0.5 consumer-1
app1 first 1 0 0 0 consumer-1-77ceb54e-e82f-42e3-bbe6-5f1d6700edaf /172.31.0.5 consumer-1
app1 first 2 0 0 0 consumer-1-77ceb54e-e82f-42e3-bbe6-5f1d6700edaf /172.31.0.5 consumer-1Inicialmente, o primeiro consumer está recebendo as mensagens de todas as partições. Agora vamos ligar os outros dois consumers:
docker run --name consumer2 --rm -it --net=cp-all-in-one_default lensesio/fast-data-dev:2.3 bash
docker run --name consumer3 --rm -it --net=cp-all-in-one_default lensesio/fast-data-dev:2.3 bashEm cada um, escutar na fila first, no grupo app1:
kafka-console-consumer --bootstrap-server broker:29092 --topic first --group app1
Com a opção --group app1 todos os consumers estarão no mesmo consumer group.
|
Podemos ver que agora, as partições estão divididas entre os 3 consumers:
kafka-consumer-groups --bootstrap-server localhost:9092 --group app1 --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
app1 first 1 0 0 0 consumer-1-77ceb54e-e82f-42e3-bbe6-5f1d6700edaf /172.31.0.5 consumer-1
app1 first 2 0 0 0 consumer-1-d4bee1bc-a792-413b-8e46-f161681a187b /172.31.0.6 consumer-1
app1 first 0 0 0 0 consumer-1-3d496a66-6534-49b4-82a7-c99fb0a08e6b /172.31.0.7 consumer-1Podemos produzir mensagens, e verificar que as mensagens com a mesma chave são enviadas para o mesmo consumer:
>1:chave 1
>2:chave 2
>3:chave 3
>4:chave 4Por padrão os consumers não mostram as chaves, pois geralmente a chave é colocada na mensagem também.
Para receber todas mensagens enviadas e ainda na fila, executar no kafka-client:
kafka-console-consumer --bootstrap-server localhost:9092 --topic first --from-beginningPara visualizar os grupos de consumidores, podemos executar:
kafka-consumer-groups --bootstrap-server localhost:9092 --list
app5
app2
app1
app4
app3Visualizar os membros de um determinado grupo:
kafka-consumer-groups --bootstrap-server localhost:9092 --group console-consumer-60880 --describe —members
GROUP CONSUMER-ID HOST CLIENT-ID #PARTITIONS
console-consumer-60880 consumer-1-ac7c6289-ca58-4e68-8206-b84733f149cf /172.17.0.1 consumer-1 5Depois de mandar novas mensagens, descrever o grupo app1 para verificar quais offsets em quais partições serão lidas:
kafka-consumer-groups --bootstrap-server localhost:9092 --group app1 --describeMostrar log (docker-compose logs -f broker) com o rebalance das partições, após adicionar e remover consumers:
[2020-03-07 22:18:46,366] INFO [GroupCoordinator 0]: Preparing to rebalance group app1 in state PreparingRebalance with old generation 4 (__consumer_offsets-30) (reason: Adding new member consumer-1-ca11c549-9549-4142-8878-5fe3891ed11b with group instanceid None) (kafka.coordinator.group.GroupCoordinator)
[2020-03-07 22:18:48,054] INFO [GroupCoordinator 0]: Stabilized group app1 generation 5 (__consumer_offsets-30) (kafka.coordinator.group.GroupCoordinator)
[2020-03-07 22:18:48,056] INFO [GroupCoordinator 0]: Assignment received from leader for group app1 for generation 5 (kafka.coordinator.group.GroupCoordinator)
[2020-03-07 22:18:48,575] INFO [GroupMetadataManager brokerId=0] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)Segmentos e Limpeza de Logs
Os Topics são divididos em partições, e as partições dividas em segmentos. Cada segmento é um arquivo. O último segmento é o ativo, os novos offsets são adicionados nesse segmento.
Os segmentos são fechados, desativados, quando chegam a um determinado tamanho ou depois de ficarem ativos durante um tempo determinado. Isso é controlado com os parâmetros log.segment.bytes, 10MB por padrão, e log.segment.ms, por padrão não tem valor, os segmentos são fechados somente por tamanho. Com os arquivos de segmento são criados dois arquivos de índice: um para localizar os offsets e um índice de data/hora (timestamp) para localizar as mensagens por data.

Os arquivos podem ser visualizados na pasta de dados de Kafka (/var/lib/kafka/data/ no container broker).
Os dados em um cluster Kafka expiram de acordo com uma política. Existem duas políticas:
-
delete (o padrão), que apaga os dados baseado:
-
No tempo (padrão = 1 semana)
-
No tamanho (padrão = -1, ou seja, infinito)
-
-
compact: que guarde o último valor relacionado com uma chave
Essa política pode ser aplicada via configuração na criação de uma fila.
O Log Compactation garante que o último valor relacionado com uma chave em uma determinada partição sempre esteja disponível. Permite diminuir o tamanho do log.
Exemplo de criação de uma fila com com log compactado:
kafka-topics --bootstrap-server localhost:9092 --create --topic log-compactation --partitions 1 --replication-factor 1 --config cleanup.policy=compact --config min.cleanable.dirty.ratio=0.001 --config segment.ms=5000Resumo das configurações utilizadas
| Opção | Descrição |
|---|---|
cleanup.policy |
delete (padrão) ou compact |
min.cleanable.dirty.ratio |
Frequência com a qual o log é limpo, entre 0 e 1 por padrão 0.5, ou seja, 50% do tempo. Maior o valor menos tentativas de limpeza, e log que tende a ficar maior. |
segment.ms |
Período de tempo em ms que o Kafka força o log a fechar um segmento. Por padrão 604800000, 1 semana. |
A lista de configuração está disponível em: https://kafka.apache.org/documentation/#topicconfigs
Depois iniciar um producer para a fila log-compactation criada acima:
kafka-console-producer --broker-list broker:29092 --topic log-compactation --property "parse.key=true" --property "key.separator=:"Escutar a fila com o comando:
kafka-console-consumer --bootstrap-server broker:29092 --topic log-compactation --property "print.key=true"Enviar dados a partir do producer:
>a:1000
>b:1500
>a:2000
>a:3000
>b:2500Os dados são apresentados no consumer:
a 1000
b 1500
a 2000
a 3000
b 2500Agora pare o consumer e inicie ele novamente pedindo para receber os dados desde o início:
kafka-console-consumer --bootstrap-server broker:29092 --topic log-compactation --from-beginning --property "print.key=true"
b 1500
a 3000
b 2500Como podemos ver para somente o último valor da chave a é retornado. Pare novamente o consumer, e execute o seguinte comando na sua máquina para visualizar os logs do Kafka:
docker logs -f --tail 100 brokerAdicione um novo valor no producer:
b:3500Observe os logs do Kafka:
[2020-03-08 18:52:49,035] INFO [ProducerStateManager partition=log-compactation-0] Writing producer snapshot at offset 5 (kafka.log.ProducerStateManager)
[2020-03-08 18:52:49,036] INFO [Log partition=log-compactation-0, dir=/var/lib/kafka/data] Rolled new log segment at offset 5 in 1 ms. (kafka.log.Log)
[2020-03-08 18:52:49,386] INFO Cleaner 0: Beginning cleaning of log log-compactation-0. (kafka.log.LogCleaner)
[2020-03-08 18:52:49,387] INFO Cleaner 0: Building offset map for log-compactation-0... (kafka.log.LogCleaner)
[2020-03-08 18:52:49,400] INFO Cleaner 0: Building offset map for log log-compactation-0 for 1 segments in offset range [4, 5). (kafka.log.LogCleaner)
[2020-03-08 18:52:49,400] INFO Cleaner 0: Offset map for log log-compactation-0 complete. (kafka.log.LogCleaner)
[2020-03-08 18:52:49,401] INFO Cleaner 0: Cleaning log log-compactation-0 (cleaning prior to Sun Mar 08 18:39:59 UTC 2020, discarding tombstones prior to Sat Mar 07 18:39:56 UTC 2020)... (kafka.log.LogCleaner)
[2020-03-08 18:52:49,401] INFO Cleaner 0: Cleaning log log-compactation-0 (cleaning prior to Sun Mar 08 18:39:59 UTC 2020, discarding tombstones prior to Sat Mar 07 18:39:56 UTC 2020)... (kafka.log.LogCleaner)
[2020-03-08 18:52:49,402] INFO Cleaner 0: Cleaning LogSegment(baseOffset=0, size=146, lastModifiedTime=1583692796000, largestTime=1583692795180) in log log-compactation-0 into 0 with deletion horizon 1583606396000, retaining deletes. (kafka.log.LogCleaner)
[2020-03-08 18:52:49,403] INFO Cleaner 0: Cleaning LogSegment(baseOffset=4, size=73, lastModifiedTime=1583692799000, largestTime=1583692798140) in log log-compactation-0 into 0 with deletion horizon 1583606396000, retaining deletes. (kafka.log.LogCleaner)
[2020-03-08 18:52:49,409] INFO Cleaner 0: Swapping in cleaned segment LogSegment(baseOffset=0, size=146, lastModifiedTime=1583692799000, largestTime=1583692798140) for segment(s) List(LogSegment(baseOffset=0, size=146, lastModifiedTime=1583692796000, largestTime=1583692795180), LogSegment(baseOffset=4, size=73, lastModifiedTime=1583692799000, largestTime=1583692798140)) in log kafka.log.MergedLog@736bc0f7 (kafka.log.LogCleaner)No log podemos observar que foi produzida uma nova mensagem no offset 5 e em seguida que o Kafka efetuou uma limpeza no log removendo a mensagem no offset 0 (b:1500).
Spring Cloud Stream - Parte 1
Criar um novo projeto a partir de Spring Initializr, selecionar as opções Web e Cloud Stream:

No pom.xml adicionar o starter para o Binder Kafka:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>O Spring Cloud Stream tem a vantagem de abstrair o Broker (Rabbitmq, Kafka ou outro) que será utilizado em aplicações orientadas a eventos. Importante utilizar ele para poder trocar o binder, como já aconteceu em alguns clientes. O Spring Cloud Stream permite trabalhar com três modos: imperativo, funcional ou com Kafka Streams. Nesse treinamento demonstraremos os dois primeiros.
Estilo Funcional
Estilo funcional com uso de Consumer<> e Supplier<> com Spring Cloud Function.
A partir da versão 3 do Spring Cloud Stream (Horsham), está integrado com Spring Cloud Function o que permite utilizar as interfaces padrão do Java para servidor de Source, Sink e Producer:
| Classe | Função | Channel |
|---|---|---|
java.util.function.Consumer |
Sink |
input |
java.util.function.Supplier |
Source |
output |
java.util.function.Function |
Processor |
input/output |
Para isso basta definir um @Bean que implementa essas interfaces:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import java.util.Random;
import java.util.function.Consumer;
import java.util.function.Supplier;
@Configuration
public class FirstConfiguration {
private static final String[] chaves = new String[]{"1", "2", "3", "4"};
private static final Random RANDOM = new Random(System.currentTimeMillis());
private static final Logger logger = LoggerFactory.getLogger(FirstConfiguration.class);
@Bean
public Consumer<Message<String>> listenFirst() {
return mensagem -> logger.info(
String.format("%s [%s]",
mensagem.getPayload(),
mensagem.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID)));
}
@Bean
public Supplier<Message<String>> sendFirst() {
return () -> {
String chave = chaves[RANDOM.nextInt(chaves.length)];
logger.info(String.format("Enviando %s", chave));
return MessageBuilder
.withPayload(String.format("Message from Spring [%s]", chave))
.setHeader("partitionKey", chave)
.build();
};
}
}Por padrão os Supplier são chamados a cada segundo por um Poller criado pelo Spring Framework. Isso pode ser redefinido com as propriedades do Bean org.springframework.cloud.stream.config.DefaultPollerProperties:
spring.cloud.stream.poller.fixedDelay: # Delay fixo entre cada chamada do Supplier
spring.cloud.stream.poller.initialDelay: # Delay para iniciar as chamadas
spring.cloud.stream.poller.cron: # Expressão cron para o pollingQuando existe mais de um bean do tipo funcional é necessário declarar para o Spring Cloud Stream quais devem ser utilizados com a propriedade spring.cloud.function.definition. Os Beans devem estar separados por ‘;’. Existem outros operadores como '|' para combinar vários Beans por exemplo.
Para vincular um bean com uma destinação em particular deve ser usado como nome de canal <nome_do_bean>-<in ou out>-<posiçao do input ou output>. Por exemplo na classe acima temos os seguintes nomes de canais: listenFirst-in-0 e sendFirst-out-0. A configuração no application.yml da aplicação para utilizar o topic first que criamos na etapa anterior é:
spring:
cloud:
stream:
kafka:
bindings:
listenFirst-in-0:
consumer:
startOffset: latest
bindings:
listenFirst-in-0:
destination: first
group: app5
sendFirst-out-0:
destination: first
producer:
partition-key-expression: headers['partitionKey']
partition-count: 3
function:
definition: listenFirst;sendFirstO valor latest do parâmetro startOffset para o consumer permite especificar que estamos interessados em escutar somente as novas mensagens. Por padrão quando um consumer tem um grupo definido, o valor de startOffset é earliest, equivalente ao --from-beginning do kafka-console-consumer.
Outro ponto de atenção é a propriedade spring.cloud.stream.bindings.sendFirst-out-0.producer.partition-key-expression, que permite definir a chave que será utilizada no envio das mensagens para o Broker, no caso o valor contido no cabeçalho partitionKey da mensagem. Esse expression utiliza SpringEL e é possível passar o valor no corpo da resposta, por exemplo o campo id com: payload.id. Existem outras estratégias para gerar a chave que podem ser encontradas no link: https://cloud.spring.io/spring-cloud-static/spring-cloud-stream-binder-kafka/3.0.0.RELEASE/reference/html/spring-cloud-stream-binder-kafka.html#_partitioning_with_the_kafka_binder.
O parâmetro partition-count deve corresponder ao número de partições definidas na criação do topic.
O Spring Cloud Stream pode também utilizar programação reativa com a abordagem funcional. Ele utiliza para isso o framework Reactor incorporado na framework Spring desde a versão 5. Em vez de retornar diretamente os dados nos métodos das interfaces funcionais, os mesmos podem retornar fluxos reativos (interface Flux):
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import reactor.core.publisher.EmitterProcessor;
import reactor.core.publisher.Flux;
import java.util.function.Consumer;
import java.util.function.Supplier;
@Configuration
public class FirstConfiguration {
private static final Logger logger = LoggerFactory.getLogger(FirstConfiguration.class);
@Bean
public Consumer<Message<String>> listenFirst() {
return mensagem -> logger.info(
String.format("%s [%s]",
mensagem.getPayload(),
mensagem.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID)));
}
@Bean
public EmitterProcessor<Message<String>> firstProcessor() {
return EmitterProcessor.create();
}
@Bean
public Supplier<Flux<Message<String>>> sendFirst() {
return this::firstProcessor;
}
}Neste classe criamos um EmitterProcessor que poderá ser utilizado para emitir novos valores. Vamos criar um endpoint Rest que receberá a mensagem a enviar. A mensagem será enviada utilizando o método onNext do EmitterProcessor:
import org.springframework.http.HttpStatus;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.ResponseStatus;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.EmitterProcessor;
import java.util.Random;
@RestController
public class SendFirstResource {
private static final String[] chaves = new String[]{"1", "2", "3", "4"};
private static final Random RANDOM = new Random(System.currentTimeMillis());
private final EmitterProcessor<Message<String>> firstEmitterProcessor;
public SendFirstResource(EmitterProcessor<Message<String>> firstEmitterProcessor) {
this.firstEmitterProcessor = firstEmitterProcessor;
}
@PostMapping(path = "/", consumes = "*/*")
@ResponseStatus(HttpStatus.ACCEPTED)
public void handleRequest(@RequestBody String body) {
String chave = chaves[RANDOM.nextInt(chaves.length)];
Message<String> message = MessageBuilder
.withPayload(String.format("%s [%s]", body, chave))
.setHeader("partitionKey", chave)
.build();
firstEmitterProcessor.onNext(message);
}
}Notem que quando um Supplier retorna um fluxo de dados, a framework reconhece esse fato não utiliza o mecanismo de polling com intervalo, o get do Supplier é chamado uma única vez. Isso se deve ao fato que com programação reativa existe um fluxo contínuo de dados. Ainda é possível ativar o polling quando a execução do Supplier retorna um fluxo finito de dados, em vez de usar a anotação @Bean, usa-se a anotação @PollableBean.
Notem também que esse estilo dispensa do uso da anotação @EnableBinding.
Estilo Imperativo
Estilo imperativo com uso de @StreamListener e @SendTo e de MessageChannel. Uso mais antigo, que está utilizado em vários projetos com Spring Cloud Stream, na versão 3 está depreciado e será retirado em versões futuras: https://cloud.spring.io/spring-cloud-static/spring-cloud-stream/current/reference/html/spring-cloud-stream.html#spring-cloud-stream-preface-notable-deprecations e https://cloud.spring.io/spring-cloud-static/spring-cloud-stream/current/reference/html/spring-cloud-stream.html#_annotation_based_support_legacy
No caso teremos dois Channels: input e output que são os padrão do Spring Cloud Stream. Esses dois channels têm por destinação o mesmo topic first. Isso é configurado assim no application.yml:
spring:
cloud:
stream:
kafka:
bindings:
input:
consumer:
startOffset: latest
bindings:
input:
destination: first
group: app-simple
output:
destination: first
producer:
partition-key-expression: headers['partitionKey']
partition-count: 3A configuração é parecida com a do estilo funcional que vimos mais cedo.
Vamos criar uma nova classe FirstService onde receberemos e enviaremos as mensagens no nosso topic First:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Sink;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import java.util.Random;
@EnableBinding({Source.class, Sink.class})
public class FirstService {
private static final String[] chaves = new String[]{"1", "2", "3", "4"};
private static final Random RANDOM = new Random(System.currentTimeMillis());
private static final Logger logger = LoggerFactory.getLogger(FirstService.class);
private final Source source;
public FirstService(Source source) {
this.source = source;
}
@StreamListener(Sink.INPUT)
public void recebeMensagemFirst(Message<String> mensagem) {
logger.info(String.format("%s [%s]",
mensagem.getPayload(),
mensagem.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID)));
}
public void enviaMensagemFirst() {
String chave = chaves[RANDOM.nextInt(chaves.length)];
logger.info(String.format("Enviando chave: %s", chave));
source.output().send(MessageBuilder
.withPayload(String.format("Mensagem do Spring - Estilo imperativo [%s]", chave))
.setHeader("partitionKey", chave)
.build());
}
}O método recebeMensagemFirst é chamado toda vez que uma mensagem é enviada no topic first, que é a destinação . O Bean source possuí um método output() que retorna um MessageChannel que permite o envio de mensagens. Para nosso teste criaremos uma classe FirstServiceScheduler para enviar uma mensagem a cada segundo:
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
@EnableScheduling
@Component
public class FirstServiceScheduler {
private final FirstService firstService;
public FirstServiceScheduler(FirstService firstService) {
this.firstService = firstService;
}
@Scheduled(fixedDelay = 1000)
public void enviarMensagem() {
firstService.enviaMensagemFirst();
}
}Streams API e KSQL
Introdução
A API de Stream do Kafka representa um conjunto de dados ilimitado e continuamente atualizado, onde ilimitado significa "de tamanho desconhecido ou ilimitado". Assim como um tópico no Kafka, um fluxo na API do Kafka Streams é feita de uma ou mais partições de fluxo. Essa API permite o desenvolvimento de aplicações de processamento de fluxo (stream processing application) e toda a lógica de processamento é executada fora dos brokers, em microsserviços por exemplo. Como vimos no capítulo sobre Spring Cloud Stream, o mesmo tem suporte para desenvolver esse tipo de aplicação.
O KSQL é um motor de processamento SQL desenvolvido em cima da API de Stream, ele permite a criação de Streams e Tables permitindo assim filtrar, modificar e juntar dados vindos de filas do Kafka. O Servidor KSQL é separado dos brokers do Kafka e pode ser escalada independentemente.
Acessar KSQL
Vamos agora experimentar o KSQL. Iniciar um container para executar um producer:
docker run --rm -it --name producer --net=cp-all-in-one_default confluentinc/cp-server:5.4.1 bashIniciar o servidor ksql e o container com as ferramentas para conectar nele:
docker-compose up -d ksql-cliAbrir um shell no container ksql-cli:
docker exec -ti ksql-cli bashConectar no servidor ksql com o comando ksql
# ksql http://ksql-server:8088
===========================================
= _ __ _____ ____ _ =
= | |/ // ____|/ __ \| | =
= | ' /| (___ | | | | | =
= | < \___ \| | | | | =
= | . \ ____) | |__| | |____ =
= |_|\_\_____/ \___\_\______| =
= =
= Streaming SQL Engine for Apache Kafka® =
===========================================
Copyright 2017-2019 Confluent Inc.
CLI v5.4.1, Server v5.4.1 located at http://ksql-server:8088
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>Para poder executar corretamente nossos testes temos de adicionar dois parâmetros no ksql:
ksql> SET 'auto.offset.reset'='earliest';
ksql> SET 'cache.max.bytes.buffering'='20000000’;
ksql> list properties;O parâmetro auto.offset.reset serve para visualizar todas as mensagens do topic na stream.
O parâmetro cache.max.bytes.buffering serve a evitar visualizar dados desatualizados, marcados para deleção mas que ainda não foram apagados efetivamente.
KSQL permite trabalhar com fluxos de dados a partir de topics Kafka.
Criar uma stream a partir de um topic:
ksql> create stream first_stream (nome VARCHAR, credito INT) with (KAFKA_TOPIC=‘first’, VALUE_FORMAT=‘DELIMITED’);
VALUE_FORMAT define o formato dos valores no topic de origem. Existem 4 tipos de formato: DELIMITED, JSON, AVRO e KAFKA.A partir de uma stream é possível selecionar e filtrar os dados com SELECT:
ksql> select nome, credito from first_stream emit changes;A cláusula emit changes é obrigatória a partir da versão 5.4 e permite indicar que uma query é contínua e que queremos imprimir todas as mudanças (push query).
Iniciar o serviço com ksql-gen no docker-compose:
docker-compose up -d ksql-datagenEm seguida, conectar no container:
docker exec -ti ksql-datagen bashKSQL Datagen é uma ferramenta que permite simular um fluxo de dados em Streams. Vamos usar ksqlgen para gerar fluxo de dados no Topic USERPROFILE:
ksql-datagen bootstrap-server=broker:29092 schema=./userprofile.avro format=json topic=USERPROFILE key=userid maxInterval=5000 iterations=100KTables
KTables representam o estado agora, enquando as KStreams representam um fluxo contínuo de eventos.
As mensagens atualizam os dados já presentes para a mesma chave, adiciona uma nova mensagem quando não há mensagem para uma determinada chave. Na criação de uma tabela deve ser declarado qual campo corresponderá à chave.
KSQL Joins
Um join serve a mesclar dados de uma maneira parecida com o JOIN do SQL. Isso permite combinar dados oriundos de várias fontes. O resultado de um join é uma nova Stream ou uma nova Table:
-
Um join entre Streams cria uma nova Stream
-
Um join entre Tables cria uma nova Table
-
Um join entre uma Stream e uma Table cria uma nova Table
Para poder efetuar um join com uma Table o conteúdo de coluna que representa a chave deve ser igual à chave da mensagem.
create stream userprofile (userid INT, firstname VARCHAR, lastname VARCHAR, countrycode VARCHAR, rating DOUBLE) with (KAFKA_TOPIC='USERPROFILE', VALUE_FORMAT='json’);
select * from userprofile up left join countrytable ct on ct.countrycode = up.countrycode emit changes;Executar o serviço ksql-datagen que contém a ferramenta do mesmo nome e que permite gerar fluxo de dados:
docker-compose up -d ksql-datagenAcessar o container criado e começar a gerar dados:
docker exec -ti ksql-datagen bash
ksql-datagen bootstrap-server=broker:29092 schema=userprofile.avro iterations=1000 maxInterval=3000 value-format=json topic=USERPROFILE key=useridProduzir um topic COUNTRY-CSV e produzir dados nele (no container producer):
kafka-topics --bootstrap-server broker:29092 --topic COUNTRY-CSV --create --partitions 1 --replication-factor 1
kafka-console-producer --broker-list broker:29092 --topic COUNTRY-CSV --property "parse.key=true" --property "key.separator=:”
>AU:AU,Australia
>IN:IN,India
>GB:GB,UK
>US:US,United StatesCriar no container ksql a Table e verificar os dados:
create table countrytable (countrycode VARCHAR, countryname VARCHAR) with (KAFKA_TOPIC='COUNTRY-CSV', VALUE_FORMAT='DELIMITED', KEY='countrycode’);
describe extended COUNTRYTABLE;
select rowkey, countrycode, countryname from countrytable emit changes;Alterar os dados para a chave GB e adicionar uma nova entrada para BR no producer:
>GB:GB,UK
>BR:BR,BrasilNo container ksql devem aparecer mais duas mensagens. Se parar de escutar o fluxo da Table (^c), e executar novamente o select poderão constatar que aparece somente uma mensagem para a chave GB.
Agora podemos efetuar um join entre a Stream userprofile e a Table countrytable:
select * from userprofile up left join countrytable ct on ct.countrycode = up.countrycode emit changes;A medida que novos registros são gerados pelo ksql-datagen eles aparecem com os dados mesclados da Table. Se atualizarmos dados nessa Table os novos registros serão mesclados com esse novo valor.
Pode ser criada uma nova stream a partir de um select com join:
create stream userdetails as select up.firstname + ' ' + ucase(up.lastname) + ' from ' + ct.countryname + ' has a rating of ' + cast(up.rating as varchar) + ' stars' as description from userprofile up left join countrytable ct on ct.countrycode = up.countrycode emit changes;
select description from userdetails;Ponto interessante, as streams podem ser consumidas pelos Consumers:
kafka-console-consumer --bootstrap-server localhost:9092 --topic USERDETAILS --from-beginningPush queries = fazem queries constantemente e apresentam os resultados até o usuário solicitar para terminar (ctrl+c) ou até o limite (LIMIT) da query.
Pull queries (introduzido na 5.4.0) = query no estado atual do sistema, só funciona com table com agregações (exemplo: COUNT).
Exemplo de pull query, criar a Stream no ksql:
create stream driverLocations (driverId INTEGER, countrycode VARCHAR, city VARCHAR, drivername VARCHAR) WITH (kafka_topic='driverlocations', key='driverId', value_format='json', partitions=1);
insert into driverLocations (driverId, countrycode, city, drivername) VALUES (1, 'AU', 'Sydney', 'Alice');
insert into driverLocations (driverId, countrycode, city, drivername) VALUES (2, 'US', 'New York', 'Bob');
insert into driverLocations (driverId, countrycode, city, drivername) VALUES (3, 'BR', 'Brasília', 'Roberto');
insert into driverLocations (driverId, countrycode, city, drivername) VALUES (4, 'IN', 'Mumbai', 'Arun’);
insert into driverLocations (driverId, countrycode, city, drivername) VALUES (5, 'AU', 'Melbourne', 'Jack’);
create table countryDrivers as select countrycode, count(*) as numDrivers from driverLocations group by countrycode;
select * from countryDrivers where rowkey='AU';