Introdução
O que é?
O Spring um conjunto de ferramentas construídas para facilitar o desenvolvimento de Aplicações Java Enterprise.
O conjunto de ferramentas teve crescimento muito grande a ponto de possibilitar construir todo e qualquer tipo de aplicação, inclusive coordenadas de forma distribuída baseada em micro serviços e conectando essas aplicações a "Internet das Coisas (IoT)".
Portanto, o Spring é um vasto conjunto de ferramentas que auxilia a construção e publicação de aplicações. Além de Java, atualmente ele suporta inclusive Groovy e Kotlin como alternativas.
Seu principal foco é o suporte de infra-estrutura no nível da aplicação. Enquanto as equipes de desenvolvimento podem se concentrar em lógicas de negócio e utilizar as variadas ferramentas prontas para entregar o valor pretendido.
O que pode ser construído?
Com as ferramentas do Spring é possível construir vários tipos de aplicações como por exemplo:
-
REST Apis
-
WebSockets
-
Web Applications
-
Streaming
-
Batch tasks
-
Cloud microsservices
Principais ferramentas
Dentre a vastidão das possibilidades do uso do Spring, temos alguns conjuntos de ferramentas que merecem destaque pela sua frequência, utilidade e praticidade dentro do ambiente das aplicações web modernas.
Spring Framework
| É o núcleo para os outros frameworks. Provê características fundamentais para o desenvolvimento de aplicações web. |

-
Injeção de dependências
-
Controle de eventos
-
Internacionalização de aplicações (i18n)
-
Validação de dados e informações
-
Programação orientada a aspectos (AOP)
-
Ferramentas de teste: contexto de testes, mock de objetos entre outros
-
Controle transacional
-
Suporte à acesso de dados: DAOs (Data Access Objects), conexões JDBC, mapeamento objeto relacional (ORM), processamento e escrita de XMLs e etc
Spring Boot
| Spring Boot applications são desenhadas para serem executadas "stand-alone", com servidores embutidos, autoconfiguradas e prontas para entrar em produção. |

-
Sem necessidade de softwares extras como servidores de aplicação
-
Possuem servidores embutidos, podem ser simplesmente executadas sem necessidade de deploy em um servidor avulso
-
Configura automaticamente bibliotecas de terceiros sempre que possível
-
Possui geração de métricas como healthchecks e configurações externalizadas
-
Sem necessidade nenhuma de configurações em XML (Terror dos desenvolvedores)
| A grande vantagem do Spring Boot é a facilidade de configuração (frequentemente nem é necessária) que muitas vezes ocorre simplesmente com uma alteração de classpath (adição de dependência). |
Spring Cloud
| Spring Cloud é um conjunto de ferramentas para facilitar aos desenvolvedores a implementar os padrões de sistemas distribuídos. Possibilita a coordenação das aplicações em qualquer ambiente distribuído incluindo a máquina do desenvolvedor. |

-
Configuração distribuída e versionada
-
Servidor de descoberta e registro de serviços
-
Roteamento de aplicações
-
Chamadas de serviço para serviço
-
Balanceamento de carga entre instâncias
-
Circuit Breakers: possibilidade de desativar uma funcionalidade em cenários de falhas
-
Message brokers (envio de mensagens entre serviços) distribuídos
Spring Data
| O Spring Data é voltado para prover um modelo baseado em Spring para acesso a dados. Simplificando o acesso à dados a bancos relacionais e não relacionais. |
-
Abstrações de repositórios e mapeamento de objeto customizado
-
Construção de queries dinâmicas baseadas no nome dos métodos
-
Suporte para auditoria
-
Possibilidade de customização dos repositórios
-
Facilidade de integração usando configurações java ou xml
Dentre seus módulos podemos destacar:
-
Spring Data Commons: Fornece uma base núcleo para os outros módulos do Spring Data
-
Abstração poderosa de repositórios
-
Geração dinâmica de queries
-
Suporte para auditoria
-
Possibilidade de customização de repositório
-
-
Spring Data JDBC: Suporte a uso de JDBC (Java Database Connectivity) diretamente
-
Operações de CRUD
-
Suporte à anotações
@Query
-
-
Spring Data JPA: Suporte a uso de JPA (Java Persistence API) facilitando e já disponibilizando uma completa camada de acesso a dados pronta.
-
Sofisticado suporte a repositórios baseados em Spring e JPA
-
Suporte a paginação, ordenação e execução de queries dinâmicas
-
Validação de queries em tempo de boostrap da aplicação
-
-
Spring Data LDAP: Provê abstração familiar e consistente de repositórios para acesso a LDAP
-
Mapeamento por anotações
-
Implementação de interfaces de repositórios suportando queries customizadas.
-
-
Spring Data Elasticsearch: Provê integração com o mecanismo de busca do Elasticsearch
-
Disponibilização do
ElasticsearchTemplatepara aumento de produtividade para operações comuns -
Mapeamento baseado em anotações
-
Implementação automática de repositórios suportando customização
-
Spring Security
| O Spring Security é um framework de autenticação e controle de acesso extremamente poderoso. |

-
Fácil customização
-
Suporte para autenticação e autorização
-
Integração com API Servlet
-
Possibilidade de integração com Spring MVC
-
Proteção contra ataques
Let’s get it on !
Dentro da aplicação que temos no repositório, vamos criar os pacotes:
-
br.com.basis.treinamentosuperior.domain.entity -
br.com.basis.treinamentosuperior.domain.repository -
br.com.basis.treinamentosuperior.service -
br.com.basis.treinamentosuperior.service.impl -
br.com.basis.treinamentosuperior.web.rest
| Não se esqueça de ir utilizando os atalhos aprendidos para importar as classes e facilitar o trabalho. |
Na sequência vamos criar as seguintes classes / interfaces:
-
Dentro do pacote
servicevamos criar a interfaceProvaService. -
Dentro do pacote
service.implvamos criar a classeProvaServiceImpl. -
Dentro do pacote
domain.repositoryvamos criar a interfaceProvaRepository. -
Dentro do pacote
domain.entityvamos criar a classeProva. -
Dentro do pacote
web.restvamos criar a classeProvaResource. -
Dentro do pacote
web.dtovamos renomear a classeTreinamentoDTOparaProvaDTO.
| Não se esqueça de renomear também o teste e as variáveis do teste para manter o código coerente. Use as formas de busca que você já aprendeu para verificar se o refactor foi finalizado. |
Adicione no pom.xml a dependência do Spring Data JPA conforme a seguir:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>Criando uma simples consulta
Faça o Maven Update do projeto para que ele compute a nova dependência e
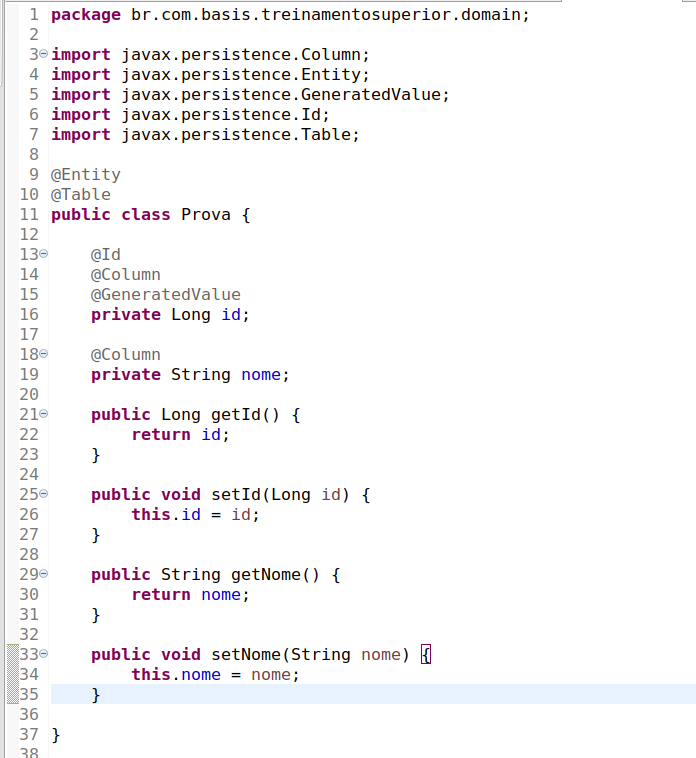
na sequência vamos na classe Prova e vamos adicionar os atributos
id Long e nome String, criando também os getters e setters.
Feito isso vamos anotar a classe conforme a seguir:
| Esse treinamento não abordará as anotações da JPA que estamos utilizando, mas vamos utilizá-las para manter o treinamento real. Posteriormente você verá esse tópico com mais detalhes. |
Na sequência, vamos no ProvaRepository vamos deixá-la conforme
a seguir:
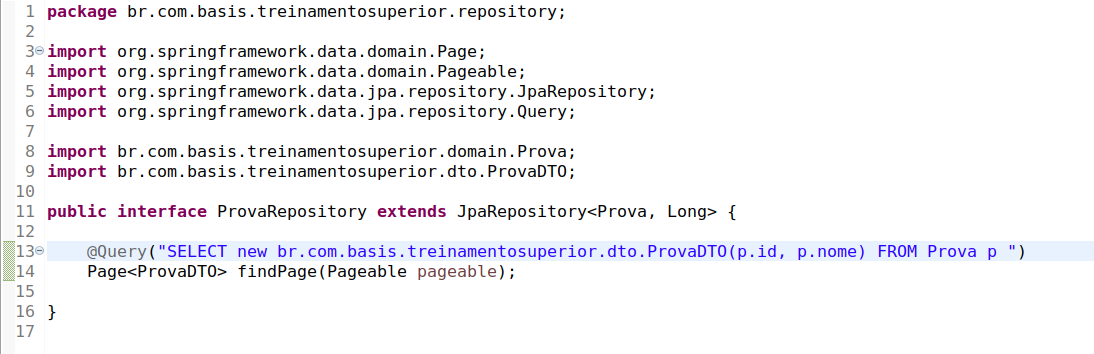
Com isso estamos utilizando a abstração que o Spring Data JPA nos provê para facilitar operações utilizando JPA.
Vamos na ProvaService e declarar o seguinte método:
Page<ProvaDTO> findPage(Pageable pageable);Certifique-se de que as classes do spring importadas são do
pacote org.springframework.data.domain do Spring.
| Estamos utilizando os objetos de paginação Pageable e Page onde o primeiro representa as informações da página que desejamos buscar e o segundo representa as informações do resultado da consulta realizada. Em tópico futuro veremos com mais detalhes as possibilidades e funcionamento da paginação utilizando Spring. |
Com o arquivo salvo, vamos à ProvaServiceImpl e vamos colocar
essa classe para implementar a interface que criamos.
Assim a IDE irá reportar um erro, passe o mouse sobre a indicação e aceite a sugestão
do quick fix: "Add unimplemented methods".
Adicione também o atributo private ProvaRepository repository; e
anote esse atributo com @Autowired.
No retorno do método que estamos criando, vamos retornar o retorno do método findPage do repository que colocamos na classe.
Assim vamos no ProvaResource declarar o private ProvaService service;,
anotar esse atributo com @Autowired e declarar o método conforme a seguir:
public ResponseEntity<Page<ProvaDTO>> findPage(Pageable pageable){
return ResponseEntity.ok(service.findPage(pageable));
}Camadas da aplicação
Com isso, criamos tudo que precisamos para fazer uma simples consulta.
Mas precisamos deixar claro a divisão de funções das camadas que acabamos de construir. Além disso, vamos utilizas as anotações do Spring para garantir seu funcionamento e organização do código.
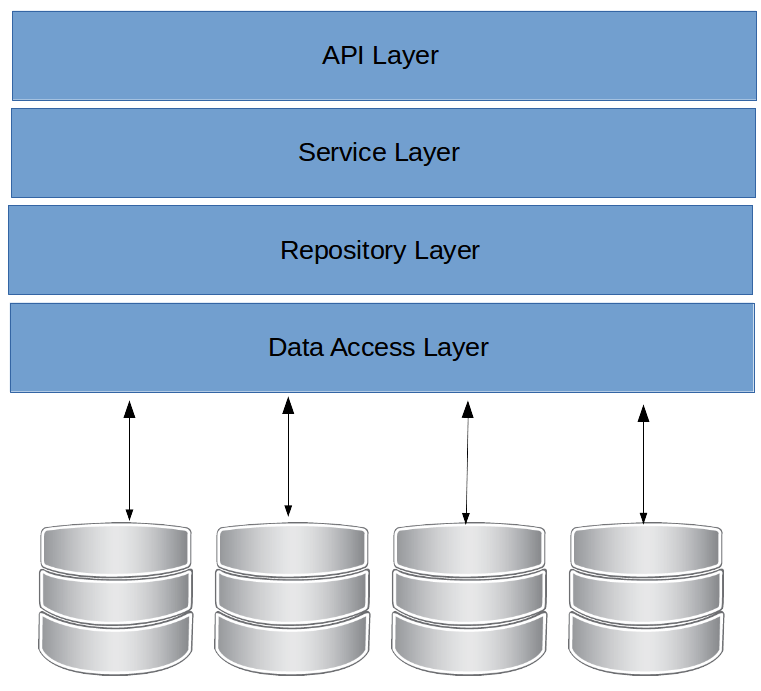
Resource
A camada de Resource é a camada responsável por tratar tudo aquilo que está relacionado à requisições HTTP. Ou seja, ela é responsável pela, manipulação e tratamento das partes de uma requisição e resposta.
| De modo geral, as partes mais importantes das HTTP Requests e Responses são Headers, Body e Method. Futuramente em tópico dedicado, veremos mais detalhes sobre o protocolo. |
Nessa camada não são implementadas regras de negócio ou de aplicação, nem consultas a banco de dados.
Portanto, em nosso ProvaResource vamos adicionar a anotação na classe
@Controller e como queremos o retorno no Body das requisições vamos
adicionar também @ResponseBody.
Já no método que criamos, vamos transformá-lo em um End Point REST,
para isso, anote a classe com @RequestMapping definindo o atributo
value com o valor "/api" e o método com a mesma @RequestMapping porém com
os valores:
@RequestMapping(method = RequestMethod.GET, value = "/page")Service / ServiceImpl
A camada de serviço é a camada onde são implementadas as manipulações de dados bem como consultas, regras de negócio, validações entre outros.
Criamos uma camada de interface e uma camada de implementação para nos garantir flexibilidade e abstração da implementação que será desenvolvida.
Portanto na ProvaServiceImpl vamos anotá-la com @Service.
Repository
A camada de repository representa os objetos de acesso a dados (DAO, Data Access Objects), por eles é feita a comunicação com o banco de dados.
O ProvaRepository é uma extensão da classe JpaRepository e por tanto
já possui uma grande variedade de métodos criadas e prontas para
serem utilizadas.
Assim vamos anotar essa classe com @Repository.
Domains
As entidades que ficam na camada de domain, refletem o modelo do banco de dados, ou seja, representam o Mapeamento Objeto-Relacional (ORM - Object-Relational Mapping) do banco de dados da aplicação.
Essas classes são utilizadas para representar registros do banco e portanto não devem deixar a camada de serviço.
Executando a consulta
Feito as anotações necessárias, compile a aplicação e verifique sucesso utilizando o script Maven que foi criado anteriormente.
Utilize o Boot Dashboard inicie a aplicação e acompanhe o log.
Finalizando, e tudo correndo bem, acesse o browser na URL
localhost:8080/api/page e você verá um JSON (em formato de texto)
do retorno do método que foi criado.
| Se desejar, copie o retorno do browser em um visualizador online de json para ver melhor as informações retornadas em formato de objeto. |
Adaptações
Com a consulta funcionando, vamos fazer algumas adaptações no código.
Primeiro, vamos nas classes de Resource e Service, remover a anotação @Autowired,
alterar os campos que devem ser injetados como final.
Assim a IDE irá mostrar como erro a falta de inicialização desses campos. Para resolver, crie um construtor que inicializa esses campos a partir dos parâmetros do mesmo tipo conforme a seguir:

Faça o mesmo para o ServiceImpl com o Repository. A seguir, coloque um breakpoint em ambos os construtores e na sequencia inicie o serviço em modo de Debug.
Durante o Startup da aplicação você verá que o construtor do ServiceImpl será invocado, e logo na sequência, o construtor do Resource será invocado.
| Assim são feitas as injeções de dependências do Spring, ele cria os beans mais internos e na sequência usa esses para instanciar os que dependem deles. Todos esses beans são gerênciados pelo Spring e "vivem" dentro do ApplicationContext (Contexto da Aplicação). |
Libere os breakpoints deixando a execução acontecer e verifique novamente o endpoint no browser, ele segue funcionando normalmente.
É mais interessante utilizarmos construtores para a injeção de dependências do que
a anotação @Autowired pois isso facilita o entendimento do código e
o desenvolvimento de testes de integração.
|
Spring Managed Beans
Mas quem são os Beans gerenciados pelo Spring?
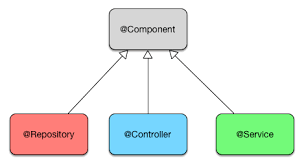
Se acessar as anotações que utilizamos, @Service, @Repository e @RestController (Acessar também a @Controller)
verá um ponto em comum. A anotação @Component. Repare que todas elas são Stereotypes do Spring.
Cada um desses Stereotypes representa uma camada da aplicação:
-
Repository: Camada de persistência -
Service: Camada de serviço / negócio -
Controller: Camada de apresentação
Ressaltando que o Component é equivalente a um Stereotype genérico.
Criando dados dentro da aplicação
De forma semelhante a consulta que fizemos, vamos fazer outro endpoint para disparar a inserção de dados para que possamos consultá-los.
Crie um endpoint GET em /create retornando um ResponseEntity<ProvaDTO>
(return ResponseEntity.ok(service.create())), que invoca um método do
Service / ServiceImpl com o seguinte código:

Assim, acesse a URL localhost:8080/api/create quantas vezes desejar e você verá o registro
que foi criado.
Cada vez que esse endpoint é acessado, a API está construída para gerar uma nova entidade Prova e armazenar no banco de dados.
| A aplicação que estamos utilizando cria e se conecta em um banco de dados em memória que estamos utilizando para facilitar o setup do treinamento. Portanto, caso você reinicie ou pare a aplicação os dados inseridos serão perdidos. |
Na sequência, acesse o endpoint /api/page para ver a consulta dos dados.
Profiling
As aplicações Spring são extremamente flexíveis e customizáveis, para demonstrar um pouco desse potencial, vamos utilizar os profiles Spring.
Repare que no log de startup da aplicação, logo no início o Spring informa quais profiles está utilizando. Verifique seu log, logo no início (provavelmente terceira linha) você verá algo como:
b.c.b.t.TreinamentoSuperiorApplication : The following profiles are active: dev,h2
Isso significa que a aplicação está executando segundo as configurações previstas
nos profiles dev e h2.
Crie a TreinamentoProvaServiceImpl estendendo a ProvaServiceImpl e anote-a
com @Profile("treinamento").
Coloque o construtor dessa classe para invocar o construtor da segunda classe
e na superclasse crie um método público para acessarmos o ProvaRepository (getter).
Assim implemente apenas método create (sobrescrevendo o da superclasse)
para não setar o nome da Prova como LocalDateTime.now().toString()
mas sim como LocalDate.now().toString().
Na sequência anote classe original com @Profile("!treinamento")
(Note o símbolo de negação !).
Finalizando, inicie a aplicação e verifique através dos endpoints:
-
O profile spring no início do log.
-
As provas estão sendo criadas com ou sem o horário.
Agora vamos forçar o uso do profile treinamento alterando o environment da aplicação.
Vá na edição as configurações do serviço no Boot Dashboard, na aba Environment selecione new:
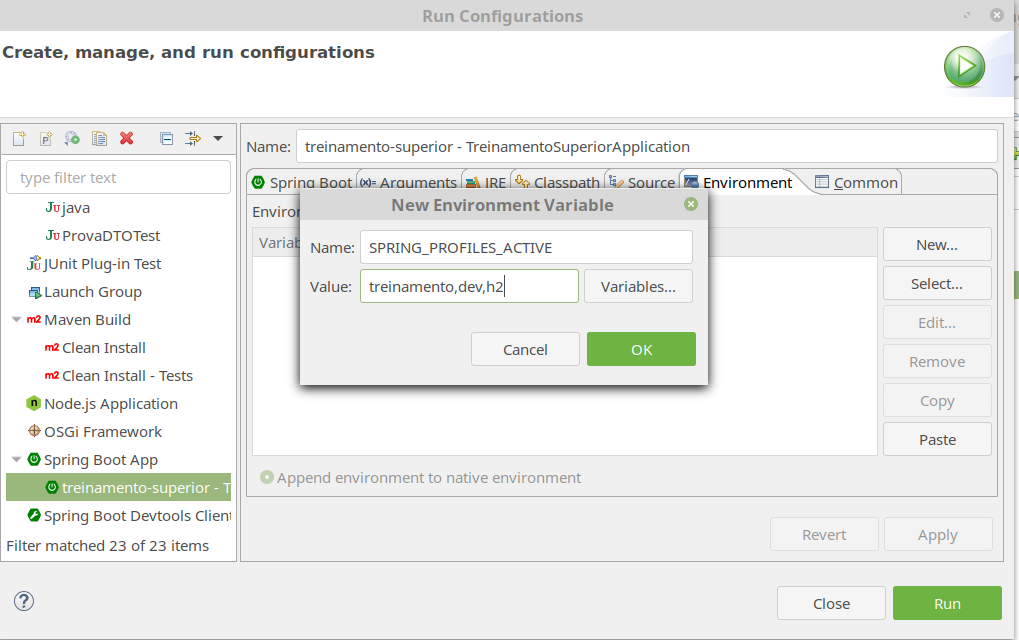
Execute a aplicação e faça as mesmas verificações que foram feitas anteriormente.
| Caso tenha dúvidas sobre o que aconteceu, é interessante colocar breakpoints nos métodos de ambas as classes e acompanhar a execução da aplicação. |
Com isso, conseguimos associar um Spring Bean (ProvaServiceImpl ou TreinamentoProvaServiceImpl)
à um profile do Spring. Esse artifício é bastante útil principalmente em
ambientes que diferem em determinados aspectos um do outro.
É importante ressaltar que no ProvaResource não está definido especificamente
qual o Spring Bean que será utilizado, mas sim aceitando um ProvaService. Dessa forma, a
aplicação é quem irá gerenciar qual será injetado.
|
Condicionando Spring Beans
Remova a variável do Environment da aplicação e remova as anotações @Profile de ambas as classes e o getter que foi criado.
Remova a anotação @Service da TreinamentoProvaServiceImpl, crie o pacote
br.com.basis.treinamentosuperior.config e a classe BeanConfiguration dentro dele.
Nessa classe injete com @Autowired um ProvaRepository e crie um método público conforme
a seguir:
@Bean
@ConditionalOnMissingBean(ProvaService.class)
public ProvaService provaService() {
return new TreinamentoProvaServiceImpl(provaRepository);
}Resumindo, estamos definindo um Bean do tipo ProvaService utilizando a implementação da TreinamentoProvaServiceImpl e condicionando
à não existência de nenhum outro Bean desse tipo.
Assim, execute a aplicação e faça novamente as verificações.
Na sequência, comente a anotação @Service da ProvaServiceImpl para que ela não seja escaneada pelo Spring (por ser um
Service) e utilize a implementação padrão que definimos no
BeanConfiguration.
Retorne a aplicação para o estado anterior removendo a classe TreinamentoProvaServiceImpl,
o pacote recém criado e as alterações feitas na ProvaServiceImpl.
Essas são funcionalidades básicas (existem muitas outras possibilidades, basta ver as
anotações iniciadas em @Conditional…) que dão muita flexibilidade a customização
as aplicações Spring.
|
E com isso, você já aprendeu uma segunda forma de definição de Spring Beans.
Arquivos de configuração
O Spring utiliza principalmente 2 tipos de arquivos de configuração: .yml e .properties. Veremos agora como alterar propriedades utilizando esses formatos de arquivos.
Procure e abra o arquivo application.yml e veja as propriedades dentro dele relacionadas à:
-
Configurações de log
-
Configurações da aplicação
-
Configurações de banco e JPA como: conexão do banco, dialeto da JPA, cache entre outros
| Os frameworks Spring, principalmente os autoconfiguráveis utilizam essas propriedades para definições e customizações que forem necessárias. Cada framework que foi apresentado anteriormente (e também os que não foram apresentados aqui) possui uma variada gama de propriedades e customizações disponíveis. Portanto é muito importante consultar as documentações no intuito de adequar as ferramentas às necessidades da aplicação. |
Procure responder as seguintes perguntas olhando esse arquivo e fazendo as pesquisas que achar conveniente:
O que significa o nível de log definido no arquivo?
Significa que todas as classes filhas do pacote org.springframework
estão com o log no nível DEBUG.
Qual é o banco de dados que estamos utilizando?
Onde está ele se não foi instalado nada em seu computador?
Estamos utilizando um banco H2. Esse banco fica em memória.
O que acontece e em que momentos acontece se o parâmetro show-sql
for alterado para false?
O log do sistema não irá exibir as queries executadas por ele
nas operações de banco como salvar e consultar.
Que profiles estão ativos na aplicação?
Estão ativos os profiles dev e h2.
Para ativar o profile treinamento colocamos a variável de ambiente
SPRING_PROFILES_ACTIVE, mas isso poderia ser feito diretamente na variável
correspondente no application.yml.
|
Hierarquia de profiles
Na sequência, vamos criar junto ao application.yml o arquivo application-no-queries.properties.
Dentro dele, insira a chave conforme:

A diferença na forma de escrita desses arquivos é que o .yml é
escrito de forma hierárquica, aproveitando os nós pai, e no .properties
os nós pai são replicados.
|
Se você iniciar a aplicação e executar os endpoints que criamos, verá que as queries ainda estão sendo exibidas no console, pois não ativamos o profile ainda.
Portanto, no application.yml, inclua também o profile no-queries, reinicie a aplicação,
confira os profiles e verifique as queries.
Os profiles, podem levar consigo novos arquivos de configuração como acabamos de
fazer e sobrescrever as propriedades comuns.
Ou seja, se existe um profile x é importante verificar a existência de arquivos
application-x (.yml ou .properties).
Faça um novo teste, alterando a propriedade show-sql para true e adicione a propriedade
spring.jpa.properties.hibernate.format_sql=true e verifique novamente o comportamento.
| Em caso de conflito de propriedades entre os vários arquivos de configuração de profiles diferentes, os profiles que vem por último irão sobrescrevendo os anteriores. |
Remova as alterações feitas.